15 de abril de 2009
Em Cornell, um grupo de investigação desenvolveu um sistema automático que deduz leis da física [1].
O vídeo explica tudo, mas resumindo de forma breve, o método consiste em filmar o sistema físico a interpretar. Daí retira-se informação acerca do movimento desse sistema, através do tratamento das imagens, seguindo o percurso de determinados pontos. Essa informação é depois inserida num algoritmo que a tenta descrever com equações. O programa desenvolve-se em várias interacções que vão pontuando as equações que melhor descrevem a essa informação.
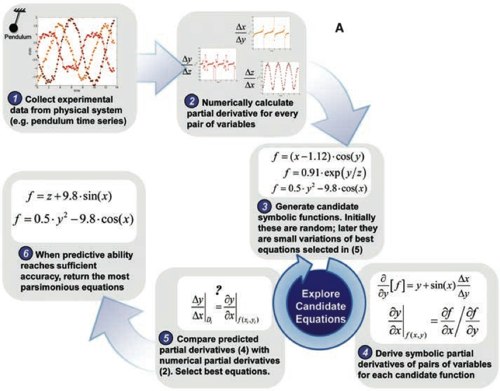
O que quero destacar é que este método não deduz, nem teoriza os fundamentos físicos universais subjacentes para descrever o sistema em análise. Apenas capta dados — muitos — e usa a capacidade de processamento dos computadores para escolher a equação que melhor descreve esses dados.
O exemplo que quero agora mencionar, é o do Mitocheck. Um projecto que pretende descobrir e analizar todos os genes humanos envolvidos na divisão celular (mitose) de células eucarióticas. Uma das partes fundamentais é a identificação de genes relevantes. Para isso Jan Ellenberg, Rainer Pepperkok e os seus grupos desenvolveram um método automatizado que verifica o todos os genes humanos [2][3]. A forma como isso é feito é a seguinte: cultivam-se células em meios que silenciam (inactivam) um gene dessas células de cada vez (usando uma técnica denominada RNA interferência). Isto é feito num espaço físico pequeno (alguns milímetros de diâmetro), onde vivem poucas células, porque o número de genes é muito grande. Se o espaço físico não fosse pequeno seriam necessárias instalações gigantescas para guardar todas as culturas celulares, correspondentes a todos os genes que se pretend silenciar. Depois, todas estas culturas são filmadas: a vida das células é documentada. Se algo no processo de divisão celular acontecer mal (por exemplo, a célula não se dividir, ou a célula suicidar-se a seguir à divisão etc.) isso significa que o gene silenciado é relevante para o processo. É um pouco como tirar peças do carro, uma a uma, e tentar ligá-lo a ver se ainda funciona. A jante não fará diferença, mas um carburador sim. Mais tarde estudar-se-ão um a um esses genes para determinar exactamente as funções que desempenham. Este processo resulta em centenas de milhares de filmes, dezenas de Terabytes de informação.
Os cientistas desenvolveram depois um programa de computador que analisa um a um estes filmes, anotando-os, isto é, marcando o estado em que estão cada uma das células filmadas. Podem ver na imagem abaixo um exemplo onde células em divisão (amarelas) são distinguidas de células em crescimento (verdes):
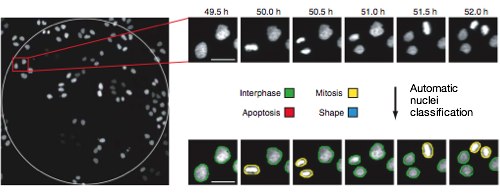
Mais uma vez, o que me interessa destacar é a utilização de sistemas automatizados que analizam dados (neste caso filmes), detectando eventos e tendências.
Esta é uma das grandes vantagens da informática: a capacidade de analizar brutalidades de dados. Já todos sabemos isso no que à computação diz respeito, isto é ao mero cálculo. As folhas de Excel comportam linhas e linhas, colunas e colunas de números. A facturação e os inventários de stocks foram simplificados e automatizados de forma impressionante. Mas será que conseguimos tirar nova informação doutro tipo de dados? Sim. Dois dos exemplos são os que mostrei acima. Neste caso, os dados não são os consumos de electricidade de clientes da PT, mas filmes de carrinhos a andar para trás e para a frente, ou células a reproduzirem-se.
Nos dias de hoje, todos nós depositamos continuamente quantidades astronómicas de informação nos servidores que constituem a internet. Não é só nomes, moradas, endereços de email e datas de nascimento. É todo o conjunto de coisas que procuramos no Google, as músicas que ouvimos no Last.fm ou as fotografias que colocamos no Facebook. Esse é todo um manancial gigantesco de informação que só agora começa a ser utilizado de forma totalmente nova. Por exemplo, a Google afirma conseguir prever a evolução epidemiológica da gripe, antes mesmo da análise que os observatórios médicos fazem por recolha de amostras. Isto por simplesmente conseguirem monitorizar as pesquisas que as pessoas fazem no seu motor de busca relacionadas com a doença [4]. Aqui está um exemplo do nível de actividade epidemiológica publicado pela Google:
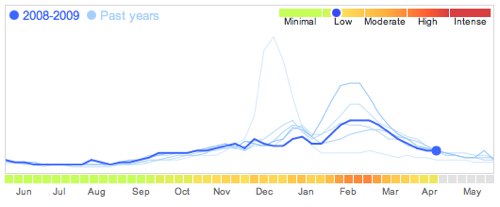
No entanto, temos de nos preparar para muito mais que daqui advirá, para o bem e para o mal. Não me surpreenderia se o Facebook já vendesse a empresas serviços que mostram em tempo real a adopção dos produtos que vendem, especificando o alcance geográfico e a demografia dos consumidores. Três por cento da população mundial está inscrita nesta rede social. A empresa que detém o Facebook tem a maior lista de ligações sociais alguma vez registada. Lembro que a Igreja foi a primeira a criar census, através dos registos de baptismos. Mas não me fico por aqui: não me custa acreditar que num futuro próximo, alguém começará a prever tendências sócio-económicas através da análise das expressões faciais ou dos tons de voz nos vídeos depositados em sites como o YouTube. Não creio que seja o acesso individual à informação que vá permitir estas previsões (embora isso levante problemas muito complicados). Mas é precisamente o enorme conjunto de informações, com uma granularidade que nenhum recenseamento de nenhum Instituto Nacional de Estatística alguma vez conseguiu ter, que vai dar a possibilidade de monitorização e previsão de tendências a um grau nunca antes visto. E agora imaginem quando a esta informação biográfica, se começar a acoplar informação geográfica e informação geracional. Será que aí iremos começar a questionar o nosso próprio livre-arbítrio?
Já agora, aqui fica informação sobre o que Facebook considera sua (deles) propriedade.
Referências
[1] – Distilling Free-Form Natural Laws from Experimental Data Science vol. 324, nº 5923, pp. 81-85 (2009)
[2] – Mitocheck
[3] – High-throughput RNAi screening by time-lapse imaging of live human cells Nature Methods 3, 385 – 390 (2006)
[4] – Google Flu Trends